数据来自Titanic - Machine Learning from Disaster
读取数据 1 2 3 4 5 6 7 import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport warningswarnings.filterwarnings('ignore' ) sns.set(style='whitegrid' )
1 2 train = pd.read_csv('../data/train.csv' , index_col='PassengerId' ) train.head()
EDA 1 2 sns.barplot(x='Pclass' , y='Survived' , data=train)
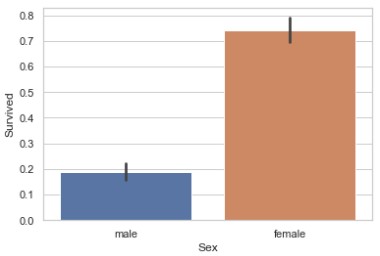
1 2 sns.barplot(x='Sex' , y='Survived' , data=train)
1 2 3 4 5 age_kde = sns.FacetGrid(train, hue='Survived' , aspect=3 ) age_kde.map(sns.kdeplot, 'Age' , shade=True ) age_kde.set(xlim=(0 , train['Age' ].max())) age_kde.add_legend()
1 2 sns.barplot(x='SibSp' , y='Survived' , data=train)
1 2 sns.barplot(x='Parch' , y='Survived' , data=train)
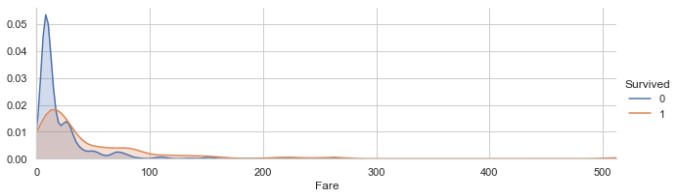
1 2 3 4 5 fare_kde = sns.FacetGrid(train, hue='Survived' , aspect=3 ) fare_kde.map(sns.kdeplot, 'Fare' , shade=True ) fare_kde.set(xlim=(0 , train['Fare' ].max())) fare_kde.add_legend()
Fare的分布是偏斜的,需要进行对数处理
1 2 sns.barplot(x='Embarked' , y='Survived' , data=train)
将训练集和测试集合并进行数据清洗 1 2 test = pd.read_csv('../data/test.csv' , index_col='PassengerId' ) test.head()
1 2 full = train.drop('Survived' , axis=1 ).append(test) full.shape
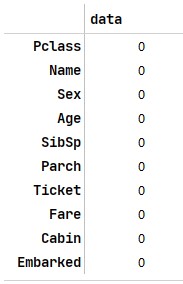
Age, Fare, Cabin, Embarked有缺失值,需要填补
1 2 full['Cabin' ] = full['Cabin' ].fillna('Unknown' )
1 full['Embarked' ].value_counts()
1 2 full['Embarked' ] = full['Embarked' ].fillna('S' )
1 full[full['Fare' ].isnull()]
1 2 full['Fare' ] = full['Fare' ].fillna(full[(full['Pclass' ] == 3 ) & (full['Embarked' ] == 'S' )]['Fare' ].mean())
用随机森林填补Age
1 2 3 4 5 6 7 8 age_use = full[['Pclass' , 'Sex' , 'Age' , 'SibSp' , 'Parch' , 'Fare' , 'Embarked' ]] age_train = age_use[~age_use['Age' ].isnull()] age_test = age_use[age_use['Age' ].isnull()] age_y = age_train['Age' ] age_train = age_train.drop('Age' , axis=1 ) age_test = age_test.drop('Age' , axis=1 ) age_X_train = pd.get_dummies(age_train) age_X_test = pd.get_dummies(age_test)
1 2 3 4 from sklearn.ensemble import RandomForestRegressorrfr = RandomForestRegressor(random_state=42 , n_estimators=100 ) rfr.fit(age_X_train, age_y) rfr.score(age_X_train, age_y)
1 2 age_pred = rfr.predict(age_X_test) full.loc[full['Age' ].isnull(), 'Age' ] = age_pred
特征工程 1 2 full['logFare' ] = full['Fare' ].apply(lambda x: np.log(x) if x > 0 else 0 ) sns.kdeplot(full['logFare' ])
1 2 full['Title' ] = full['Name' ].apply(lambda x: x.split(',' )[1 ].split('.' )[0 ].strip()) full['Title' ].value_counts()
1 2 full.loc[~full['Title' ].isin(['Mr' , 'Miss' , 'Mrs' , 'Master' ]), 'Title' ] = 'Other' full['Title' ].value_counts()
SibSp和Parch合并,创造新特征
1 2 full['FamilySize' ] = full['SibSp' ] + full['Parch' ] + 1 full['IsAlone' ] = full['FamilySize' ].apply(lambda x: 1 if x == 0 else 0 )
根据年龄创造是否为儿童的特征
1 full['IsChild' ] = full['Age' ].apply(lambda x: 1 if x < 10 else 0 )
统计相同票号的情况,创造特征
1 full['Ticket' ].value_counts()
1 2 3 tic_cnt_dict = {} tic_cnt_dict = full['Ticket' ].value_counts() full['TicketCnt' ] = full['Ticket' ].map(tic_cnt_dict)
删除无用的特征
1 full_use = full.drop(['Name' , 'Ticket' , 'Fare' ], axis=1 )
独热编码,重新划分训练集和测试集
1 2 3 4 full_dum = pd.get_dummies(full_use) X_dum_train = full_dum[full_dum.index.isin(train.index.tolist())] X_dum_test = full_dum[full_dum.index.isin(test.index.tolist())] X_dum_train.shape, X_dum_test.shape
1 y_train_use = train['Survived' ].reset_index(drop=True )
互信息法筛选特征
1 2 from sklearn.feature_selection import mutual_info_classiffrom sklearn.feature_selection import SelectKBest
1 2 3 4 5 mic = mutual_info_classif(X_dum_train, y_train_use, random_state=42 ) k = mic.shape[0 ] - sum(mic <= 0 ) kmic = SelectKBest(mutual_info_classif, k).fit(X_dum_train, y_train_use) X_train_mic = kmic.transform(X_dum_train) X_train_mic.shape
1 X_test_mic = kmic.transform(X_dum_test)
1 2 np.savetxt('../data/X_train_mic.csv' , X_train_mic, delimiter=',' ) np.savetxt('../data/X_test_mic.csv' , X_test_mic, delimiter=',' )
训练模型 常用分类模型:
1 2 3 4 5 6 7 from sklearn.ensemble import RandomForestClassifierfrom sklearn.linear_model import LogisticRegressionfrom sklearn.svm import SVCfrom xgboost import XGBClassifierfrom sklearn.model_selection import train_test_split, GridSearchCVX_train, X_test, y_train, y_test = train_test_split(X_train_mic, y_train_use, test_size=0.2 , random_state=42 )
随机森林 1 2 3 4 5 rf_param = {'criterion' : ['gini' , 'entropy' ]} rf = RandomForestClassifier(random_state=42 , n_estimators=100 ) rf_cv = GridSearchCV(rf, rf_param, cv=5 ) rf_cv.fit(X_train, y_train) rf_cv.score(X_test, y_test)
1 2 3 4 5 6 7 8 rf_score = [] for i in range(5 , 11 ): rf = RandomForestClassifier(criterion='entropy' , random_state=42 , n_estimators=100 , max_depth=i) rf.fit(X_train, y_train) rf_score.append(rf.score(X_test, y_test)) plt.plot(range(5 , 11 ), rf_score) plt.show()
1 2 3 4 5 6 7 8 rf_score = [] for i in range(40 , 80 , 5 ): rf = RandomForestClassifier(criterion='entropy' , max_depth=6 , random_state=42 , n_estimators=i) rf.fit(X_train, y_train) rf_score.append(rf.score(X_test, y_test)) plt.plot(range(40 , 80 , 5 ), rf_score) plt.show()
1 2 3 rf = RandomForestClassifier(criterion='entropy' , n_estimators=60 , max_depth=6 , random_state=42 ) rf.fit(X_train_mic, y_train_use) rf_pred = rf.predict(X_test_mic)
1 2 rf_sub = pd.DataFrame({'PassengerId' : test.index.tolist(), 'Survived' : rf_pred}) rf_sub.to_csv('../result/rf.csv' , index=False )
逻辑回归 1 2 3 4 5 lr_param = {'solver' : ['liblinear' , 'lbfgs' , 'sag' ]} lr = LogisticRegression(random_state=42 ) lr_cv = GridSearchCV(lr, lr_param, cv=5 ) lr_cv.fit(X_train, y_train) lr_cv.score(X_test, y_test)
1 2 3 4 5 6 7 8 lr_score = [] for i in range(15 , 21 ): lr = LogisticRegression(random_state=42 , solver='lbfgs' , max_iter=i) lr.fit(X_train, y_train) lr_score.append(lr.score(X_test, y_test)) plt.plot(range(15 , 21 ), lr_score) plt.show()
1 2 3 4 5 6 7 8 lr_score = [] for i in np.linspace(0.001 , 0.05 , 20 ): lr = LogisticRegression(random_state=42 , solver='lbfgs' , max_iter=19 , C=i) lr.fit(X_train, y_train) lr_score.append(lr.score(X_test, y_test)) plt.plot(np.linspace(0.001 , 0.05 , 20 ), lr_score) plt.show()
1 2 3 lr = LogisticRegression(random_state=42 , solver='lbfgs' , max_iter=19 , C=0.01 ) lr.fit(X_train_mic, y_train_use) lr_pred = lr.predict(X_test_mic)
1 2 lr_sub = pd.DataFrame({'PassengerId' : test.index.tolist(), 'Survived' : lr_pred}) lr_sub.to_csv('../result/lr.csv' , index=Flse)
支持向量机 1 2 3 4 5 svc_param = {'kernel' : ['linear' , 'poly' , 'rbf' , 'sigmoid' ]} svc = SVC(random_state=42 ) svc_cv = GridSearchCV(svc, svc_param, cv=5 ) svc_cv.fit(X_train, y_train) svc_cv.score(X_test, y_test)
1 2 3 4 5 6 7 8 svc_score = [] for i in np.linspace(0.01 , 0.05 , 10 ): svc = SVC(random_state=42 , kernel='linear' , C=i) svc.fit(X_train, y_train) svc_score.append(svc.score(X_test, y_test)) plt.plot(np.linspace(0.01 , 0.05 , 10 ), svc_score) plt.show()
1 2 3 svc = SVC(random_state=42 , kernel='linear' , C=0.045 ) svc.fit(X_train_mic, y_train_use) svc_pred = svc.predict(X_test_mic)
1 2 svc_sub = pd.DataFrame({'PassengerId' : test.index.tolist(), 'Survived' : svc_pred}) svc_sub.to_csv('../result/svc.csv' , index=False )
XGBoost 1 2 import xgboost as xgbdtrain_mic = xgb.DMatrix(X_train_mic, y_train_use)
1 2 3 4 5 xgb_param = {'silent' : True , 'obj' : 'binary:logistic' , 'subsample' : 0.8 , 'max_depth' : 5 , 'eta' : 0.3 , 'gamma' : 0 , 'lambda' : 1 , 'alpha' : 0 , 'colsample_bytree' : 1 , 'colsample_bylevel' : 1 , 'colsample_bynode' : 1 , 'nfold' : 5 , 'n_estimators' : 1000 , 'seed' : 42 } num_round = 200
1 xgb.cv(xgb_param, dtrain_mic, num_round, metrics='auc' , early_stopping_rounds=50 )
1 cv_param = {'max_depth' : range(2 , 10 , 2 ), 'min_child_weight' : range(1 , 6 , 2 )}
1 2 3 xgb_cv = GridSearchCV(estimator=XGBClassifier(objective='binary:logistic' , subsample=0.8 , learning_rate=0.1 , gamma=0 , alpha=0 , colsample_bytree=1 , colsample_bylevel=1 , colsample_bynode=1 , nfold=5 , n_estimators=21 , seed=42 , silent=True ), param_grid=cv_param, scoring='roc_auc' , cv=5 ) xgb_cv.fit(X_train, y_train) xgb_cv.score(X_test, y_test)
1 cv_param = {'max_depth' : [7 , 8 , 9 ], 'min_child_weight' : [2 , 3 , 4 ]}
1 2 3 xgb_cv = GridSearchCV(estimator=XGBClassifier(objective='binary:logistic' , subsample=0.8 , learning_rate=0.1 , gamma=0 , alpha=0 , colsample_bytree=1 , colsample_bylevel=1 , colsample_bynode=1 , nfold=5 , n_estimators=21 , seed=42 , silent=True ), param_grid=cv_param, scoring='roc_auc' , cv=5 ) xgb_cv.fit(X_train, y_train) xgb_cv.score(X_test, y_test)
1 cv_param = {'gamma' : [i/10 for i in range(0 , 5 )]}
1 2 3 xgb_cv = GridSearchCV(estimator=XGBClassifier(objective='binary:logistic' , subsample=0.8 , learning_rate=0.1 , alpha=0 , colsample_bytree=1 , colsample_bylevel=1 , colsample_bynode=1 , nfold=5 , n_estimators=21 , seed=42 , max_depth=8 , min_child_weight=3 ), param_grid=cv_param, scoring='roc_auc' , cv=5 ) xgb_cv.fit(X_train, y_train) xgb_cv.score(X_test, y_test)
重新调整n_estimators
1 2 3 4 5 xgb_param = {'obj' : 'binary:logistic' , 'subsample' : 0.8 , 'max_depth' : 8 , 'learning_rate' : 0.1 , 'gamma' : 0 , 'lambda' : 1 , 'alpha' : 0 , 'colsample_bytree' : 1 , 'colsample_bylevel' : 1 , 'colsample_bynode' : 1 , 'n_estimators' : 1000 , 'min_child_weight' : 3 , 'seed' : 42 } num_round = 200
1 xgb.cv(xgb_param, dtrain_mic, num_round, metrics='auc' , early_stopping_rounds=50 )
1 2 cv_param = {'subsample' : [i/10 for i in range(1 , 10 )], 'colsample_bytree' : [i/10 for i in range(1 , 10 )]}
1 2 3 xgb_cv = GridSearchCV(estimator=XGBClassifier(objective='binary:logistic' , subsample=0.8 , learning_rate=0.1 , alpha=0 , gamma=0 , colsample_bytree=1 , colsample_bylevel=1 , colsample_bynode=1 , nfold=5 , n_estimators=26 , seed=42 , max_depth=8 , min_child_weight=3 ), param_grid=cv_param, scoring='roc_auc' , cv=5 ) xgb_cv.fit(X_train, y_train) xgb_cv.score(X_test, y_test)
1 cv_param = {'alpha' : [1e-5 , 1e-2 , 0 , 0.1 , 1 , 100 ]}
1 2 3 xgb_cv = GridSearchCV(estimator=XGBClassifier(objective='binary:logistic' , subsample=0.6 , learning_rate=0.1 , alpha=0 , gamma=0 , colsample_bytree=0.6 , colsample_bylevel=1 , colsample_bynode=1 , nfold=5 , n_estimators=26 , seed=42 , max_depth=8 , min_child_weight=3 ), param_grid=cv_param, scoring='roc_auc' , cv=5 ) xgb_cv.fit(X_train, y_train) xgb_cv.score(X_test, y_test)
1 2 3 xgbc = XGBClassifier(objective='binary:logistic' , subsample=0.6 , learning_rate=0.1 , alpha=0 , gamma=0 , colsample_bytree=0.6 , colsample_bylevel=1 , colsample_bynode=1 , nfold=5 , n_estimators=26 , seed=42 , max_depth=8 , min_child_weight=3 ) xgbc.fit(X_train, y_train) xgbc.score(X_test, y_test)
1 2 xgbc.fit(X_train_mic, y_train_use) xgb_pred = xgbc.predict(X_test_mic)
1 2 xgb_sub = pd.DataFrame({'PassengerId' : test.index.tolist(), 'Survived' : xgb_pred}) xgb_sub.to_csv('../result/xgb.csv' , index=False )
模型融合 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def get_oof (clf, x_train, y_train, x_test) : ntrain = x_train.shape[0 ] ntest = x_test.shape[0 ] from sklearn.model_selection import KFold kf = KFold(n_splits=5 , random_state=42 ).split(x_train) oof_train = np.zeros((ntrain,)) oof_test = np.zeros((ntest,)) oof_test_skf = np.empty((5 , ntest)) for i, (train_index, test_index) in enumerate(kf): x_tr = x_train[train_index] y_tr = y_train[train_index] x_te = x_train[test_index] clf.fit(x_tr, y_tr) oof_train[test_index] = clf.predict(x_te) oof_test_skf[i, :] = clf.predict(x_test) oof_test[:] = oof_test_skf.mean(axis=0 ) return oof_train.reshape(-1 , 1 ), oof_test.reshape(-1 , 1 )
1 2 3 4 rf_oof_train, rf_oof_test = get_oof(rf, X_train_mic, y_train_use, X_test_mic) lr_oof_train, lr_oof_test = get_oof(lr, X_train_mic, y_train_use, X_test_mic) svc_oof_train, svc_oof_test = get_oof(svc, X_train_mic, y_train_use, X_test_mic) xgb_oof_train, xgb_oof_test = get_oof(xgbc, X_train_mic, y_train_use, X_test_mic)
1 2 3 train_l2 = np.hstack([rf_oof_train, lr_oof_train, svc_oof_train, xgb_oof_train]) test_l2 = np.hstack([rf_oof_test, lr_oof_test, svc_oof_test, xgb_oof_test]) X_train_l2, X_test_l2, y_train_l2, y_test_l2 = train_test_split(train_l2, y_train_use, test_size=0.2 , random_state=42 )
1 2 3 4 from sklearn.tree import DecisionTreeClassifierdt = DecisionTreeClassifier(random_state=42 , max_depth=3 ) dt.fit(X_train_l2, y_train_l2) dt.score(X_test_l2, y_test_l2)
1 2 3 stack_pred = dt.predict(test_l2) stack_sub = pd.DataFrame({'PassengerId' : test.index.tolist(), 'Survived' : stack_pred}) stack_sub.to_csv('../result/stack.csv' , index=False )