统计分析是理解数据集中变量的相互关系及这些关系对其它变量的依赖情况的过程。可视化是统计分析的核心内容,因为通过合理的可视化,人类的视觉系统就能够发现反映相互关系的趋势和模式
这个教程将讨论三个seaborn函数,其中最常用的是relplot()。这是一个图水平的函数,使用两种常用的方法可视化统计关系:散点图和折线图。relplot()整合了FacetGrid及两个轴水平函数中的一个:
scatterplot()(参数kind='scatter',是默认设置)lineplot()(参数kind='line')
这些函数使用简单易懂的数据表现形式,却能够展示非常复杂的数据集结构。因为它们绘制的二维图像能够使用色调 (hue)、尺寸 (size)和风格 (style)等语义参数映射至多三个额外的变量,从而增强其表现力
1 | import numpy as np |
通过散点图关联变量
散点图是统计分析的中流砥柱。它使用一系列点描绘两个变量的联合分布,每个点代表数据集中的一个观测。通过观察散点图可以推断两个变量之间是否存在有意义的相互关系
Seaborn可以通过多种方式绘制散点图。当两个变量都是数值型时,最基础的是使用scatterplot()函数。在类别型可视化教程中会介绍专门用于通过散点图可视化类别型数据的工具。scatterplot()是relplot()中的默认kind (也可以强行设置kind='scatter'):
1 | tips = sns.load_dataset('tips') |
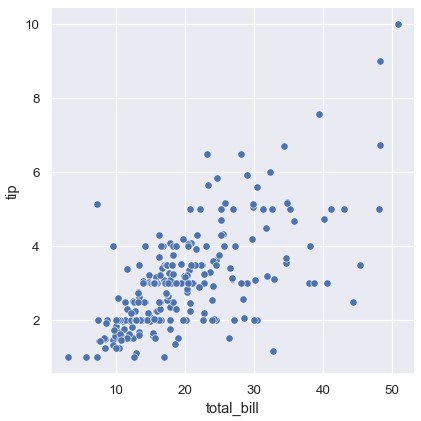
虽然散点图是二维的,可以通过把第三个变量映射为颜色在图上添加额外的维度。Seaborn称之为“色调语义” (hue semantic),因为点的颜色是有意义的:
1 | sns.relplot(x='total_bill', y='tip', hue='smoker', data=tips) |
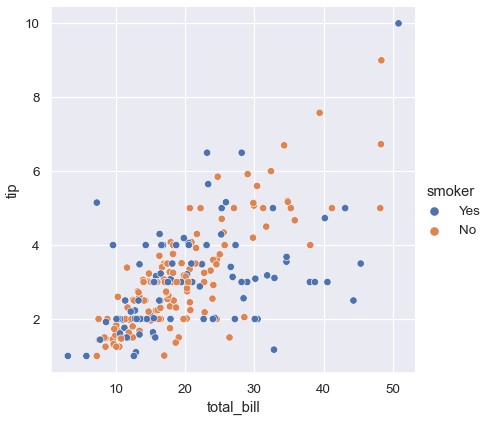
为了强化不同类别的差异,还可以为每种类别设置不同的风格的标记:
1 | sns.relplot(x='total_bill', y='tip', hue='smoker', style='smoker', data=tips) |
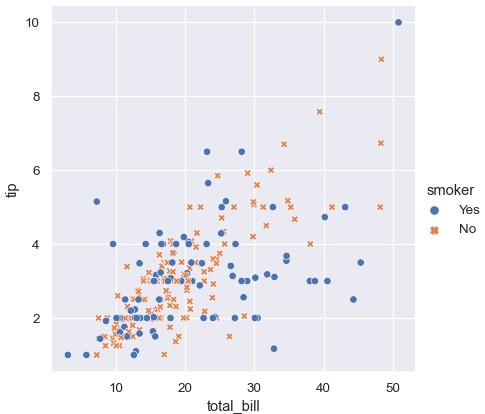
通过独立地设置每个点的色调和风格,能够展示四个变量。由于眼睛对形状的敏感度远低于颜色,这种做法要慎重:
1 | sns.relplot(x='total_bill', y='tip', hue='smoker', style='time', data=tips) |
在上述例子中,色调语义是类别型变量,所以默认使用定性调色板。如果色调语义是数值型的 (尤其是浮点类型),默认的颜色会换成连续型调色板 (sequential palette):
1 | sns.relplot(x='total_bill', y='tip', hue='size', data=tips) |
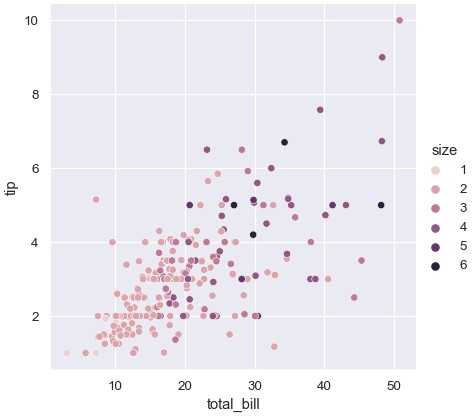
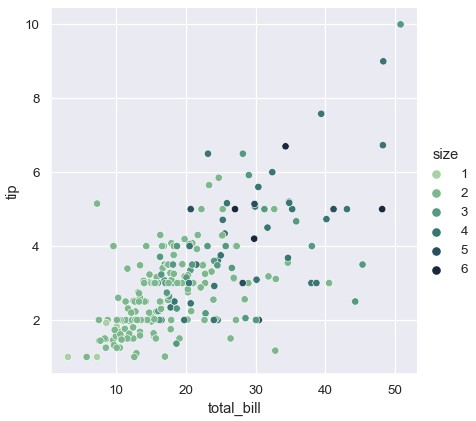
两种调色板都支持自定义配色方案,很多方法可以实现这一目标。这里使用与cubehelix_palette()交互的字符串来自定义连续型调色板:
1 | sns.relplot(x='total_bill', y='tip', hue='size', palette='ch:r=-.5,l=.75', data=tips) |
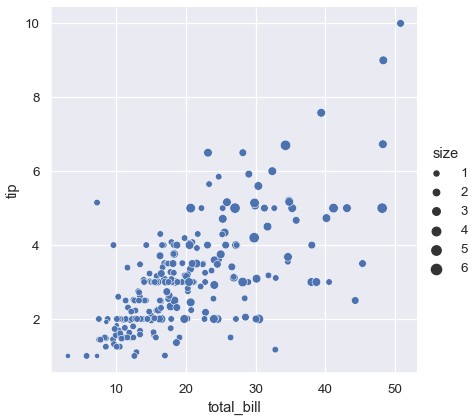
第三种语义变量改变每个点的大小:
1 | sns.relplot(x='total_bill', y='tip', size='size', data=tips) |
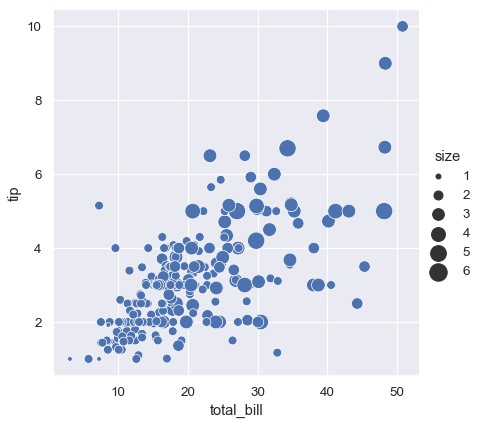
与matplotlib.pyplot.scatter()不同,点的大小并不是由变量字面上的值决定的。数据单元中一系列的数值会被标准化,映射到点的大小取值范围中,这一范围接受指定:
1 | sns.relplot(x='total_bill', y='tip', size='size', sizes=(15, 200), data=tips) |
更多通过自定义语义映射展示数据相互关系的示例见scatterplot() API
折线图强调连续性
散点图十分高效,但可视化并没有统一的最适方案。可视化方案应该根据数据集的特征及想要解决的问题进行调整。
对一些数据集来说,需要理解某个变量随时间或者类似的连续型变量的变化。在这种情况下,折线图是个不错的选择。可以直接使用lineplot()函数,或者使用relplot()设置kind='line':
1 | df = pd.DataFrame(dict(time=np.arange(500), value=np.random.randn(500).cumcum())) |
由于lineplot()假设最常用的是绘制y关于x的函数,绘制前默认将数据根据x的值进行排序。这一功能可以关闭:
1 | df = pd.DataFrame(np.random.randn(500, 2).cumsum(axis=0), columns=['x', 'y']) |
聚合及展示置信区间
在更复杂的数据集中,同一个x的值会对应多个测量值。Seaborn默认聚合每一个x值对应的多个测量值,绘制出均值及95%置信区间:
1 | fmri = sns.load_dataset('fmri') |
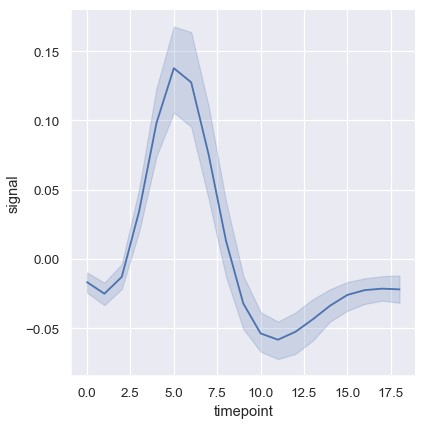
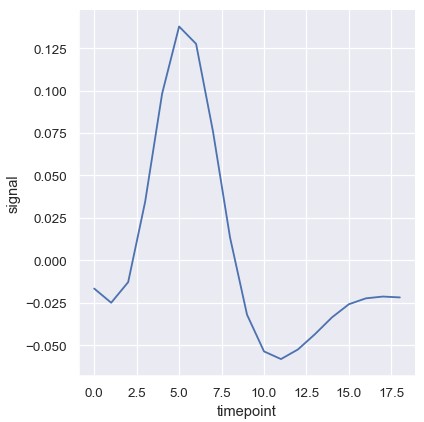
置信区间使用自举法 (bootstrap)计算,对于较大的数据集而言比较耗时。这一功能可以关闭:
1 | sns.relplot(x='timepoint', y='signal', ci=None, kind='line', data=fmri) |
对于较大的数据集,相比于绘制置信区间,另一个不错的选择是绘制每个时间点的标准偏差来展示数据的范围:
1 | sns.relplot(x='timepoint', y='signal', ci='sd', kind='line', data=fmri) |
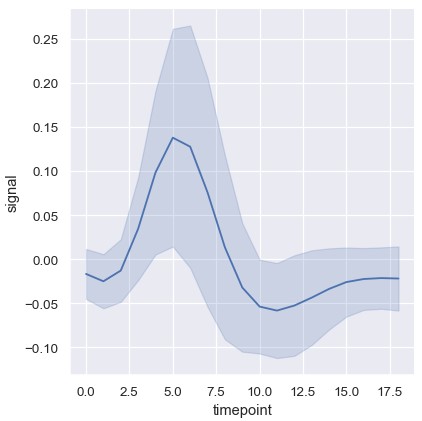
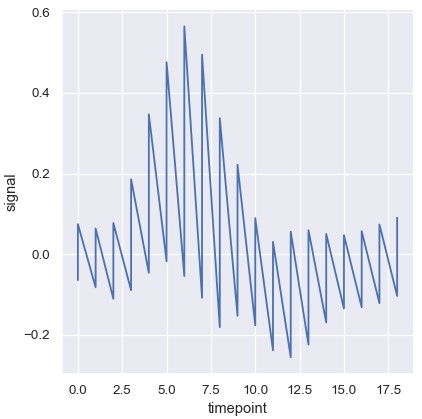
要想彻底关闭聚合功能,可以将estimator参数设为None。如果数据集中的每个x值对应多个观测,可能会产生奇怪的效果:
1 | sns.relplot(x='estimator', y='signal', estimator=None, kind='line', data=fmri) |
使用语义映射绘制数据子集
lineplot()函数与scatterplot()函数一样灵活:通过修改色调、大小和风格可以额外展示至多三个变量
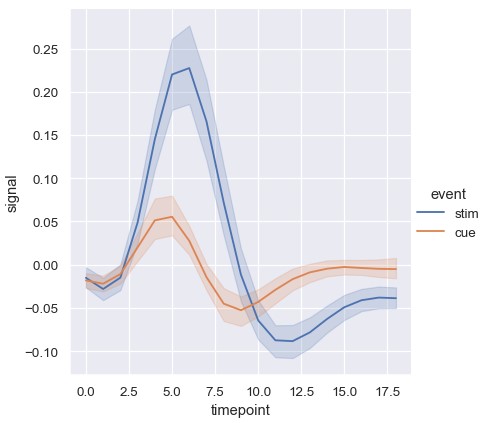
在lineplot()中使用语义参数也会决定数据进行聚合的方式。例如,添加含有两个取值的色调语义会绘制两条线和误差带,用不同的颜色区分它们所代表的数据子集:
1 | sns.relplot(x='timepoint', y='signal', hue='event', kind='line', data=fmri) |
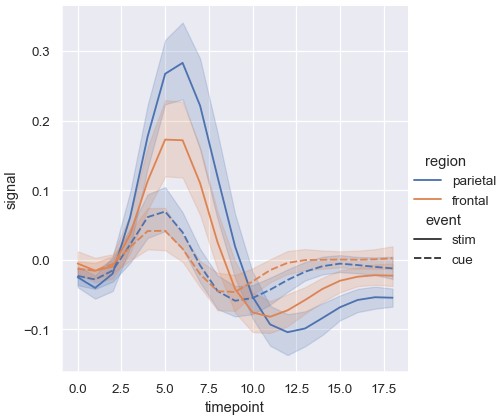
折线图添加风格语义默认改变线条的连接模式:
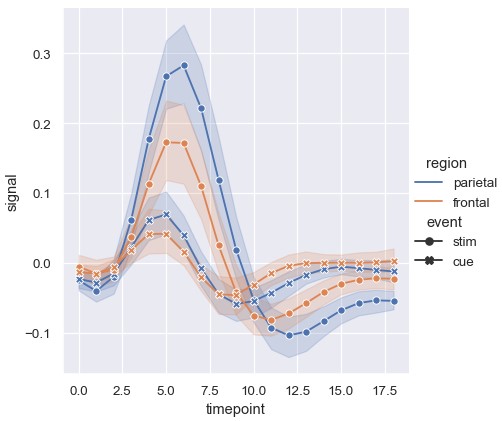
1 | sns.relplot(x='timepoint', y='signal', hue='region', style='event', kind='line', data=fmri) |
也可以根据每个数据点的标记区分各个子集,可以结合风格语义,也可以替代风格语义:
1 | sns.relplot(x='timepoint', y='signal', hue='region', style='event', dashes=False, markers=True, kind='line', data=fmri) |
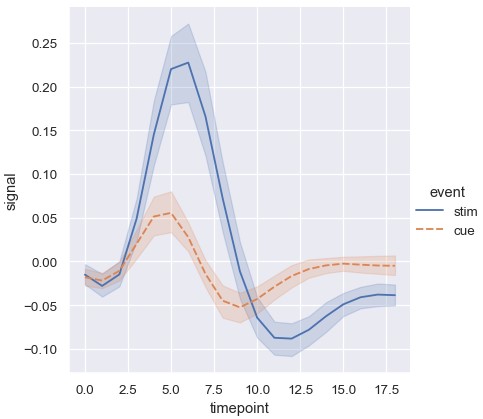
与散点图一样,折线图在使用多种语义参数的时候也要小心。虽然有时候信息量很大,但也可能过于复杂很难解读。然而,如果只是想评估一个额外的变量,也可以同时改变线条的颜色和风格。这样在黑白打印的情况下或者对于色盲人士更容易理解:
1 | sns.relplot(x='timepoint', y='signal', hue='event', style='event', kind='line', data=fmri) |
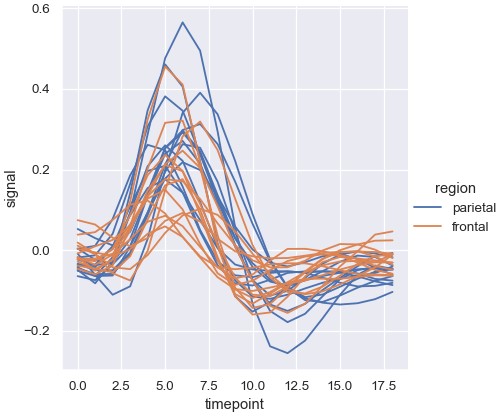
对于重复测量的数据,也可以不使用语义变量进行区分,而是单独绘制每个子集的的数据。这样可以避免图例凌乱:
1 | sns.relplot(x='timepoint', y='signal', hue='region', units='subject', estimator=None, kind='line', data=fmri.query("event == 'stim'")) |
lineplot()中,图例默认的配色方案也取决于色调语义是类别型还是数值型:
1 | dots = sns.load_dataset('dots').query("align == 'dots'") |
可能出现的问题是,即便hue变量是数值型,线性的颜色变化仍然难以区分。现在就是这种情况,hue变量的数值是进行过对数缩放的。可以传入一个列表或者字典,指定每条线对应的颜色:
1 | palette = sns.cubehelix_palette(light=0.8, n_colors=6) |
或者可以调整调色板的标准化方式:
1 | from matplotlib.colors import LogNorm |
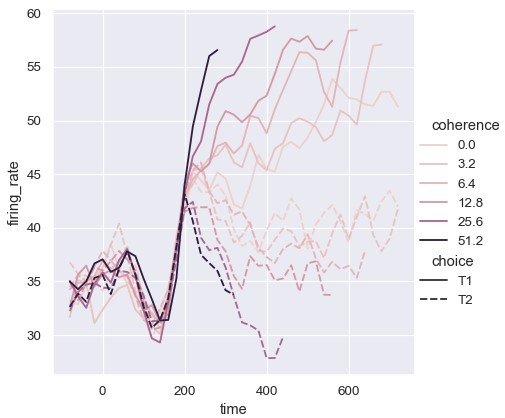
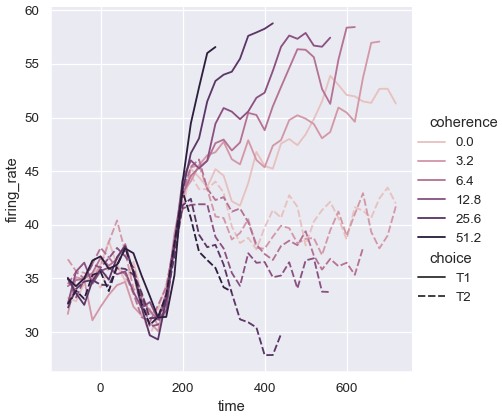
大小语义改变线的宽度:
1 | sns.relplot(x='time', y='firing_rate', size='coherence', style='choice', kind='line', data=dots) |
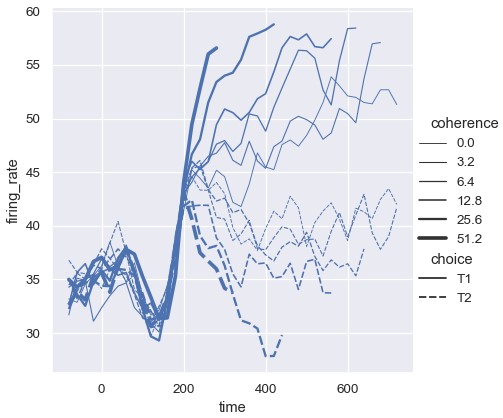
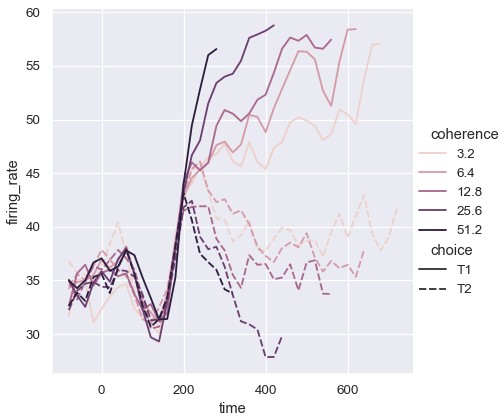
尽管size变量通常是数值型变量,但线的宽度也可以映射到类别型变量。这种用法需要小心,因为除了线的粗细很难分辨出更多信息。然而,当分组很多时,各种样式的虚线也很难分辨,所以不同的线宽可能是更好的选择:
1 | sns.relplot(x='time', y='firing_rate', size='coherence', size='choice', palette=palette, kind='line', data=dots) |
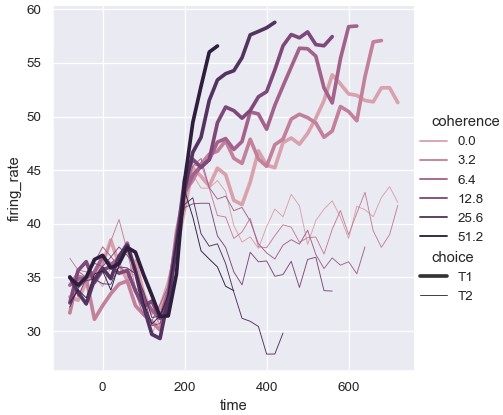
绘制时序数据
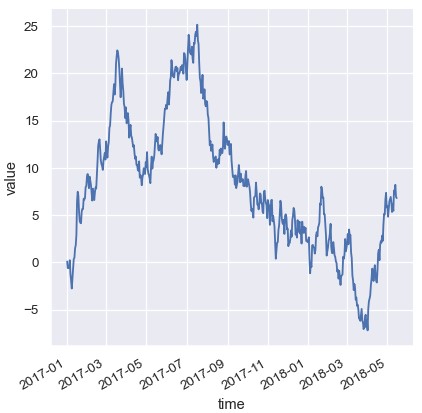
折线图经常用来可视化与真实日期时间相关的数据。这些函数把数据按照其原始格式传递到底层的matplotlib函数,这样就可以利用matplotlib对刻度标签的日期进行格式化。所有格式化过程发生在matplotlib的层面,需要参考matplotlib的文档了解其工作原理:
1 | df = pd.DataFrame(dict(time=pd.date_range('2017-1-1', periods=500), value=np.random.randn(500).cumsum())) |
通过分面展示多个相互关系
虽然这些函数能够一次性展示多种语义变量,但是这种做法并不是万能的。如果想了解两个变量的相互关系对多个变量的依赖情况应该怎么办呢
最好的办法是画多个图。由于relplot()是以FacetGrid为基础,绘制子图十分方便。如果想要展示一个额外变量的影响,可以不把这个变量设为某种语义,而是通过分面进行可视化。这意味着可以生成多个轴,然后把数据的子集分别绘制在这些轴上:
1 | sns.relplot(x='total_bill', y='tip', hue='smoker', col='time', data=tips) |
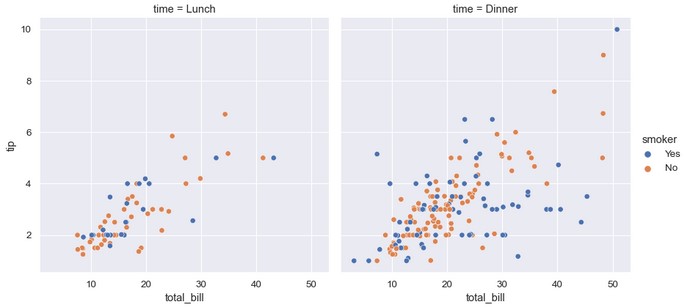
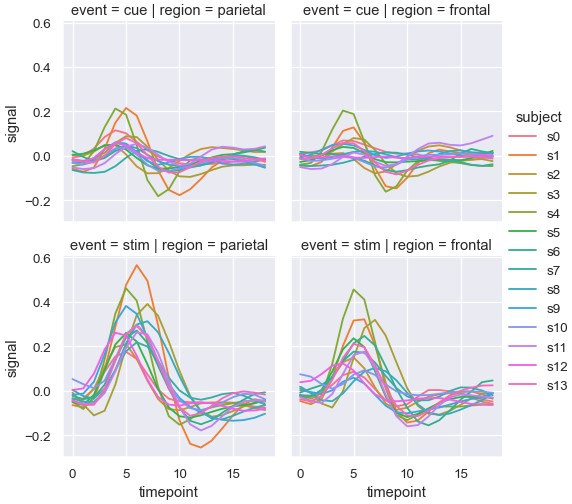
这种方式也可以展示两个额外变量的影响:一个按列分面,一个按行分面。向图片网格中添加更多轴时,可能需要缩小图片的大小。注意FacetGrid通过高度和纵横比控制每个子图的大小:
1 | sns.relplot(x='timepoint', y='signal', hue='subject', col='region', row='event', height=3, kind='line', estimator=None, data=fmri) |
如果想要评估一个变量的多个取值产生的影响,可以根据这个变量按列分面,然后将子图按行封装 (wrap):
1 | sns.relplot(x='timepoint', y='signal', hue='event', style='event', col='subject', col_wrap=5, height=3, aspect=0.75, linewidth=2.5, kind='line', data=fmri.query("region == 'frontal'")) |
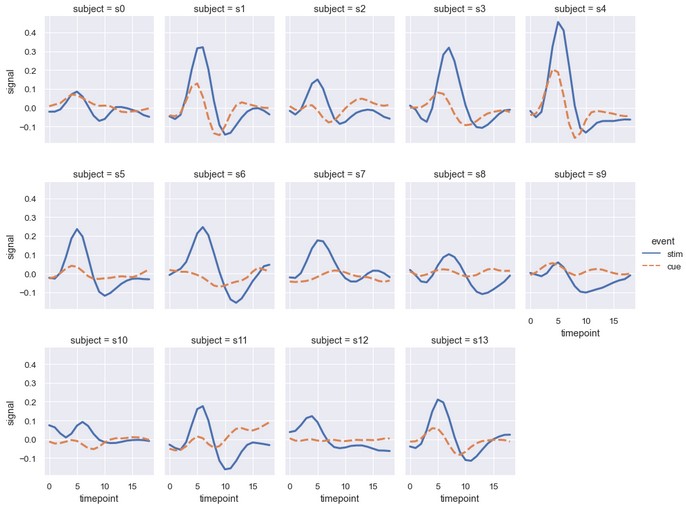
这种可视化可视化方式通常叫作格子图 (lattice plots)或小多图 (small-multiples),它非常高效,因为这种形式能够让我们同时捕捉数据的整体模式和不同模式之间的差异。当然我们应该充分利用scatterplot()和relplot()提供的各种复杂功能,但也要时刻记住,多个简单的图片通常会比一个复杂的图片更高效


