文章信息
- 题目:Targeted isolation and cultivation of uncultivated bacteria by reverse genomics
- 年份:2019
- 单位:橡树岭国家实验室,田纳西大学
- DOI:10.1038/s41587-019-0260-6
- 杂志:Nature Biotechnology (IF 36.558)
- 分类:Research article
评论
- 目的微生物表面抗原的筛选是成功分离的关键,本文提供了三种不同情况的成功案例:
- 对于研究广泛,有同源3D结构的PBP2,结合同源蛋白结构筛选抗原表位
- 对于没有同源3D结构的CpsC,根据结构预测筛选抗原表位
- 针对SR1类群,使用全长的膜外氨基酸作为抗原生产多克隆抗体
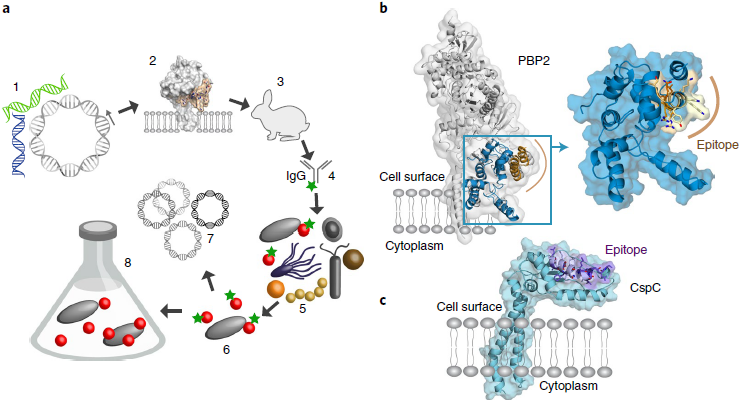
方法
样品采集与处理
采集健康人的唾液及牙周炎患者的龈沟液
口腔微生物样品按照1: 5的比例用
dental transport medium稀释,涡旋混匀1 min,1,000 g离心2 min去除大颗粒。上清过10 μm细胞筛,12,000 g离心15 min,用1 ml PBS重悬处理后的样品立即用于活细胞分选
TM7a基因组挖掘,抗原表位筛选及抗体生产
使用当时仅有的两个口腔TM7基因组TM7a和TM7c
根据COG分类,首先属于转运、细胞被膜生成及胞外结构的蛋白
将这些蛋白用
TMHMM v.2.0预测跨膜区选择有跨膜结构域的蛋白,去除注释为
hypothetical的及氨基酸数量少于100个的最终目的是找到相对较大且功能已知的蛋白
选出的117个蛋白与
Human Oral Microbiome Database的蛋白质组进行BLASTP比对48个蛋白与其它物种来源的蛋白相似性大于90%,认为可能是污染
逐个分析剩下的蛋白的跨膜结构域、胞外结构域的数量及大小、同源蛋白是否已报道3D结构及作为抗原的其它实验数据
最佳选择是青霉素结合蛋白PBP2,有高分辨率的晶体结构,且已有文献报道抗-PBP2抗体能够结合在病原微生物的表面,人类口腔微生物中的同源蛋白与TM7a的PBP2相似性为30-40%。为检测没有3D结构及抗原数据的情况下该方法的有效性,也选择了一个CpsC蛋白,属于
polysaccharide copolymerases superfamily,人类口腔微生物中的同源蛋白与TM7a的CpsC相似性不超过30%使用在线服务器预测两个蛋白的抗原区域及多肽的疏水性
ABCpred(https://webs.iiitd.edu.in/cgibin/abcpred)
BepiPred(http://www.cbs.dtu.dk/services/BepiPred/cite.php)
IEBD Analysis Resource(http://tools.immuneepitope.org/bcell)从PBP2上找到7个可以作为抗原的多肽,基于大肠杆菌PBP1b的3D结构,用PyMOL分析这些多肽的位置
最终选择了三个暴露在外面的残基最多的多肽之一(SGNIKYAKQRQKTVLTRMV)
从CpsC上找到4个可以作为抗原的多肽,由于没有3D结构,选择了位于胞外结构域的螺旋区的一个肽段(ESAIQEFKEQSKSLYGNS)
商业合成两个最终选出来的抗原多肽,在CpsC的N端和PBP2的C端加一个半胱氨酸,免疫兔子,ELISA验证抗体有效性
HiTrap Protein A HP antibody purification columns纯化IgG,Alexa Fluor 488 Antibody Labeling Kit对抗体进行荧光标记
抗-SR1抗体靶点的筛选
使用人类口腔微生物SR1 HOT345的基因组,筛选该类群的抗体靶点
选择了357个氨基酸的假想蛋白BSK20_04595,预测该蛋白有一个跨膜结构域和一个胞外结构域,胞外结构域包含LysM和CHAP结构域
选择氨基酸片段39-357作为抗原,密码子优化,过表达,蛋白纯化,兔免疫,IgG亲和纯化
口腔微生物样品免疫荧光标记及流式分选
悬浮在PBS中的口腔微生物样品,用5%羊血清及IgG混合物(兔抗-Ignicoccus IgG,兔抗-Clostridium IgG,人IgG各1 μg/ml)封闭30 min,封闭一些口腔细菌上潜在的非特异性抗体结合位点
封闭后加入0.1-1 μg/ml荧光标记的抗体,室温孵育1 h,12,000 g离心15 min,用含1%血清的PBS重悬;或者直接用含1%血清的PBS稀释至2 ml
加入到样品中之前,抗体溶液15,000 g离心5 min,小心吸取上清,降低荧光颗粒的背景
30 min后样品进行流式分选
负对照包括未标记的口腔样品(检测自发荧光)及不含微生物的空白处理(检测荧光抗体析出)
如果信号太弱,用二级标记抗体(如羊抗兔IgG)可以放大信号
口腔TM7的分离培养
选用BHI,OTEB,MTGE及TSB培养基,补加多种生长因子
ATCC 维生素,微量元素,澄清过滤的唾液,猪胃粘膜素,糖,氨基酸和核苷酸,N-乙酰胞壁酸,N-乙酰葡糖胺,丙酮酸
96孔板加200 μl培养基,分选后37 ℃培养
培养48-72 h后,用排枪吸取100 μl,过0.2 μm的96孔过滤板。用200 μl PBS冲洗,往滤膜上加20 μl TE,室温100 rpm震荡5 min。吸取10 μl细胞悬液到96孔PCR板中,加10 μl裂解液,95 ℃加热5 min。冰上冷却,加10 μl中和缓冲液。
裂解液:0.13 M KOH,3.3 mM EDTA (pH 8.0)
中和缓冲液:0.13 M HCl,0.42 M Tris (pH 7.0),0.18 M Tris (pH 8.0)使用通用引物及TM7特异引物扩增。有条带的培养物进行测序,并转接到新鲜的培养基中
所有检测到TM7的培养物都混杂着很多其它菌
固体培养基选择DMM平板补加2%葡萄糖,0.1 g/l酸水解酪蛋白和10%羊血;BHI平板补加10%羊血
分选获得的单细胞在每个平板上按10 × 10排列,37 ℃培养
培养3-5天后形成的菌落扩增测序
有杂菌的菌落重复划线,直至菌落仅包含TM7及一种宿主放线菌
TM7富集物及宿主共培养物可以在含10%二甲基亚砜的培养基中-80 ℃冻存
结果
基于抗体的口腔TM7细胞分选
- 通过流式分选,带有荧光标记的细胞占0.1-5%
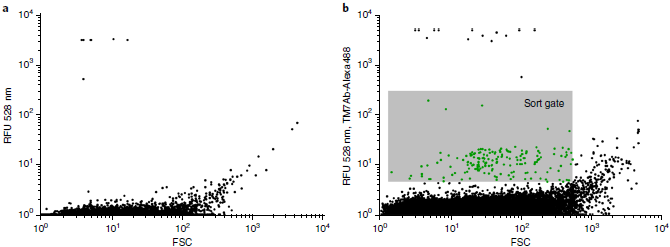
左图是未标记的样品,RFU > 10^3为自荧光沉淀/矿物质
为检测TM7是否被IgG标记,收集10-100个荧光标记的细胞,进行
多重置换基因组扩增(multiple displacement genomic amplification, MDA),然后用特异性引物进行PCR扩增MDA是一种单细胞基因组扩增技术,能对全基因组进行高保真的均匀扩增,产生10-100kb的片段,从而放大单个细菌中的DNA至模板所需的微克水平
分选获得的细胞集合中25-100%包含TM7,比例取决于不同样品及分选门参数,抗-PBP2抗体和抗-CpsC抗体都能获得TM7细胞
为增强荧光信号,覆盖尽可能多样的序列,用于培养的实验后续都进行抗-PBP2和抗-CpsC双标记
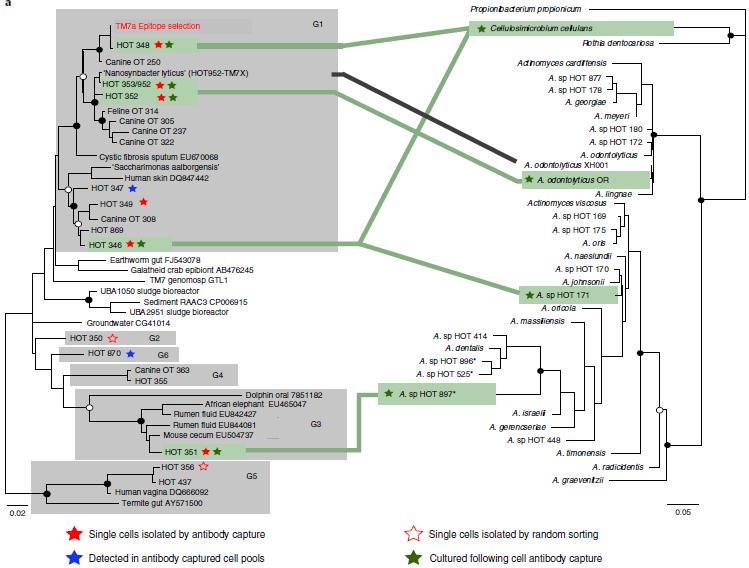
用MiSeq分析细胞集合中的物种组成,TM7丰度可高达95%,主要是类群1,3,6
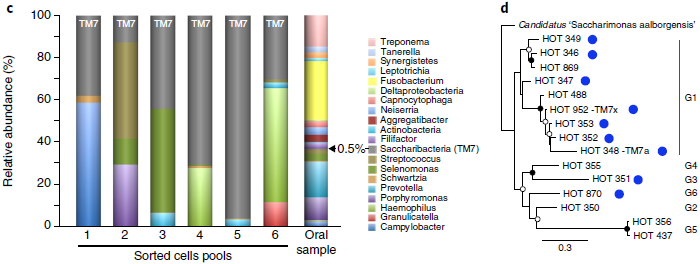
基于抗体的TM7培养
固体培养基上获得包含5种不同TM7的菌落
所有TM7阳性的菌落都包含放线菌,80%也包含链球菌,根据文献报道认为放线菌可能是宿主,链球菌由于粘附性强,可能是共分离物
TM7 HOT346和HOT348是不同的物种,但是在同一个Cellulosimicrobium cellulans菌落中检测到
多个TM7可能寄生在同一个寄主细胞上
对Cellulosimicrobium-TM7培养物进行第二轮标记和分选,获得纯的C. cellulans-TM7 HOT346共培养物
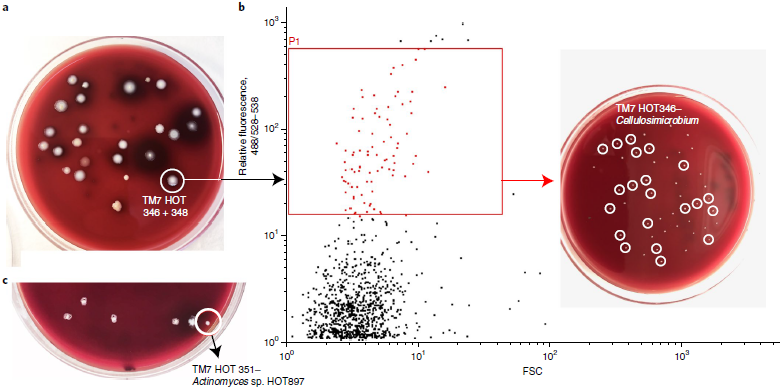
在同一个供体的唾液样本中,还获得了TM7 HOT346与Actinomyces sp. HOT171的共培养物,说明在自然环境中,TM7很可能寄生在不同属的细菌中
纯化后的TM7-放线菌共培养物可以在多种标准的富营养培养基中传代,冻存后可复苏
TM7 HOT351属于TM7类群的一个新科或新目,与Actinomyces sp. HOT897共同分离出来
A. odontolyticus XH001是TM7 HOT352和HOT952的宿主
在液体培养基中还检测到TM7 HOT347和HOT870,但是不能在固体培养基上生长,也未能鉴定其宿主
TM7物种及其放线菌宿主之间没有进化距离上的明显相关性
不同TM7可能同时寄生在相同的宿主细胞,相同TM7物种也可以寄生在不同的宿主
分离的所有TM7物种都是直径 < 0.5 μm的球菌,位于宿主细胞的表面
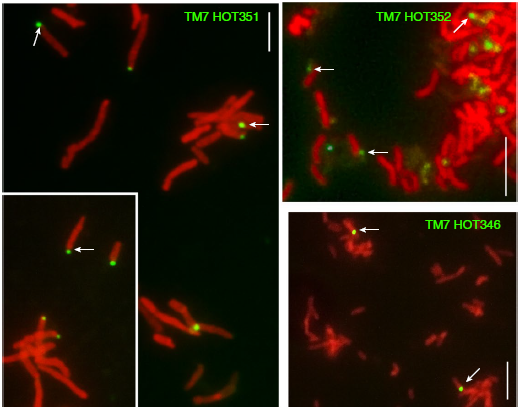
反向基因组学方法分离其它未培养的微生物
使用单细胞基因组数据SR1 HOT345,选择了一个预测的暴露于表面的糖基转移酶,也被注释为参与细胞壁合成的表面抗原
选择整个暴露的~300个氨基酸的结构域用于抗体生产
获得2个SR1培养物,都包含SR1 HOT875,共培养的细菌分别是Fusobacterium periodonticum 和 Parvimonas micra
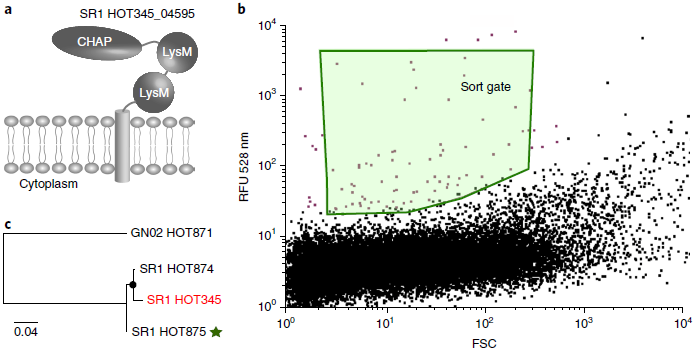
- 未能获得足量的菌体进行显微表征
反向基因组学助力单细胞基因组测序
通过对抗体标记的样品进行细胞分选及多重置换基因组扩增,从384组分选获得的细胞中得到二十多个TM7 SAGs (single-cell amplified genomes),根据16S rRNA序列分为6个物种:HOT346, HOT348, HOT349, HOT351, HOT352, HOT353/952
基因组分箱获得的MAGs通常缺少16S rRNA基因,难以与已知的物种进行系统发育分析,而SAGs不存在这个问题
共测序,组装,分析了23个SAGs,代表人类口腔微生物TM7类群中的6个类群:类群1,2,3,5
将获得的TM7 SAGs与已报道的TM7基因组进行比较基因组学分析,证实了其~0.6-1 Mb的小基因组是基因丢失造成的,这也与其寄生的生活方式相关
并不清楚开放环境中的TM7是否依赖与其它微生物的物理接触
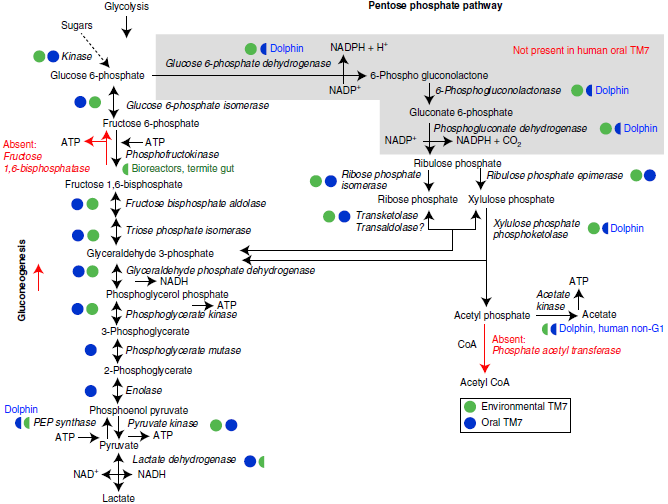
目前所有TM7基因组都缺少电子传递链,但可能存在没有呼吸功能的专性发酵代谢
开放环境中的TM7物种编码近乎完整的磷酸戊糖途径,偶联异型乳酸发酵,从而通过底物水平磷酸化产生NADPH和ATP。人类口腔TM7缺少磷酸戊糖途径中起始NADPH产生的关键酶及异型乳酸发酵的关键酶:磷酸木酮糖磷酸转酮酶。因此,口腔TM7可能利用己糖-戊糖的相互转化并主要通过糖酵解产生ATP
讨论
只要找到合适的表面抗体,就能从复杂群落中获取低丰度的目标微生物活细胞,有助于后续进行高通量的培养参数筛选
TM7的分离选择了短的肽链作为抗原,但也可以用全长的蛋白作为抗原生产多克隆抗体,从而靶向膜蛋白的多个位点。这样能够增加结合的概率,但可能降低结合的特异性
抗体标记筛选的细胞也可以用于其它微液滴、ichips等高通量培养方法进行后续处理
不可能所有微生物都能直接培养,但从靶向细胞获得的单细胞基因组数据对于推测理化性质、完善基因组信息及最终成功培养都至关重要
