blast结果下载
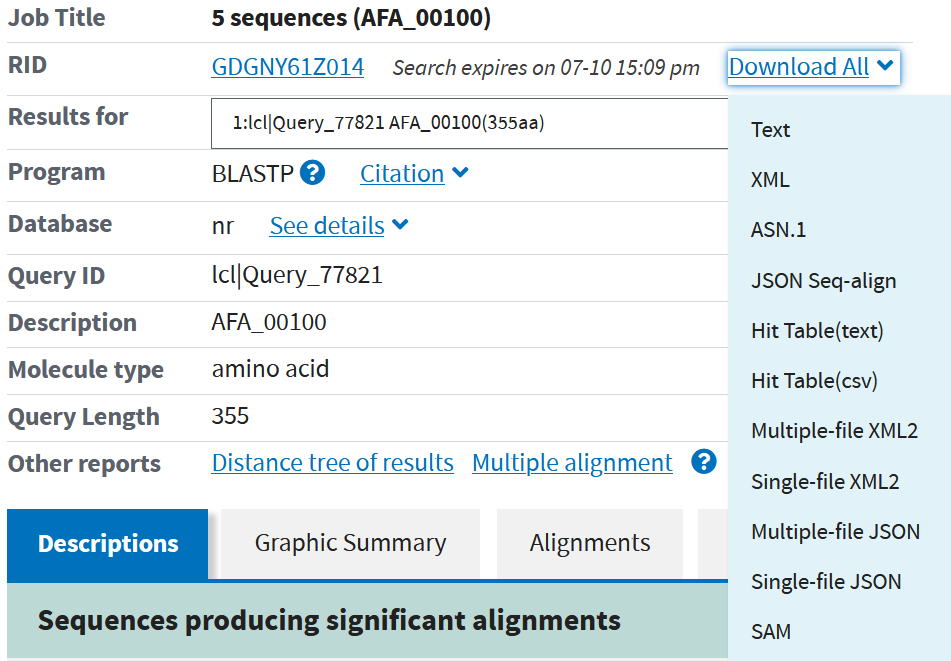
比对结果界面点击Download All,出现下拉菜单

分别下载XML及Hit Table(csv)
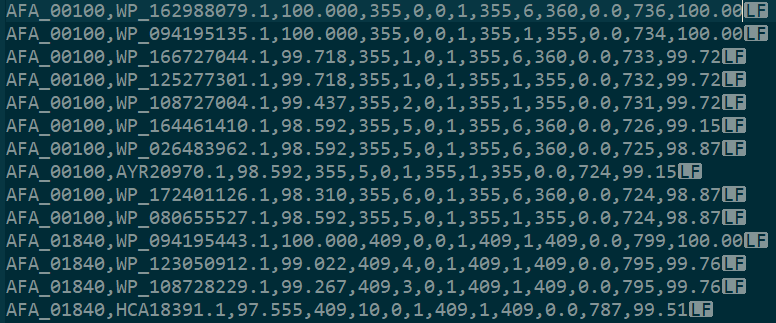
csv格式结果如下:
从左到右各列分别为:query id, subject id, identities, alignment length, mismatches, gap opens, qstart, qend, sstart, send, evalue, bit score, positives
csv数据缺少比对结果的注释
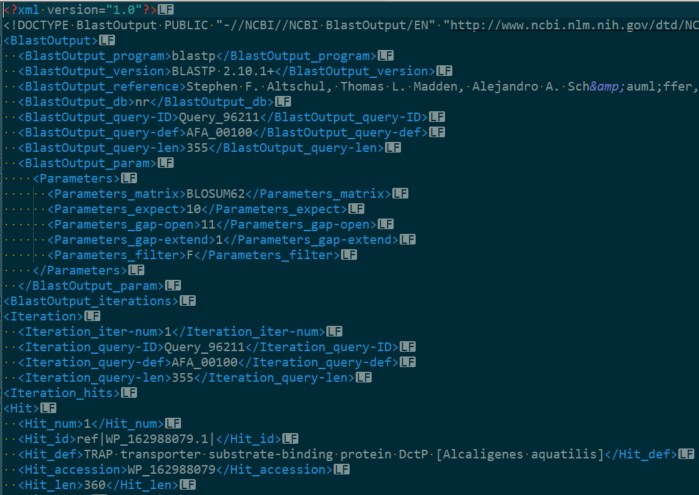
xml格式结果如下:
比对结果的描述为Hit_def标签
xml解析
parse方法:可接收文件名或打开的文件对象,生成ElementTreegetroot方法:获取根节点,生成Element。每个节点有tag, attrib, text, 节点可迭代,可通过索引获取子节点
整理blast比对结果
从xml文件中提取比对结果的注释,通过登录号与csv文件匹配合并,生成带有比对结果描述的文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| from xml.etree import ElementTree
import pandas as pd
class ParseXML(object):
def __init__(self, xmlpath):
self.xmlpath = xmlpath
def getRoot(self):
tree = ElementTree.parse(self.xmlpath)
return tree.getroot()
def getAnno(self, root):
acc_list = []
for elem in root[8].iter(tag='Hit_accession'):
acc_list.append(elem.text + '.1')
anno_list = []
for elem in root[8].iter(tag='Hit_def'):
anno_list.append(elem.text)
return acc_list, anno_list
def getRes(self, outfile):
root = self.getRoot()
acc_list, anno_list = self.getAnno(root)
res = pd.DataFrame({'subject id': acc_list, 'annotation': anno_list})
res.to_csv(outfile, sep='\t', index=False)
return res
class ParseCSV(object):
def __init__(self, csvpath):
self.csvpath = csvpath
def readCSV(self):
df = pd.read_csv(self.csvpath, names=['query id', 'subject id', 'identities', 'alignment length', 'mismatches', 'gap opens', 'qstart', 'qend', 'sstart', 'send', 'evalue', 'bit score', 'positives'], header=0)
return df
def mergeRes(self, res, outfile):
df = self.readCSV()
merged = pd.merge(df, res, how='inner', on='subject id', sort=False, copy=False)
merged.to_csv(outfile, sep='\t', index=False)
return merged
if __name__ == '__main__':
xmlparse = ParseXML('F0YAA561014-Alignment.xml')
res = xmlparse.getRes('acc_anno.txt')
csvparse = ParseCSV('F0YAA561014-Alignment-HitTable.csv')
merged = csvparse.mergeRes(res, 'merged.txt')
|